United States of America
United States of America
Sorry, yes. All my music is on f:\Music\
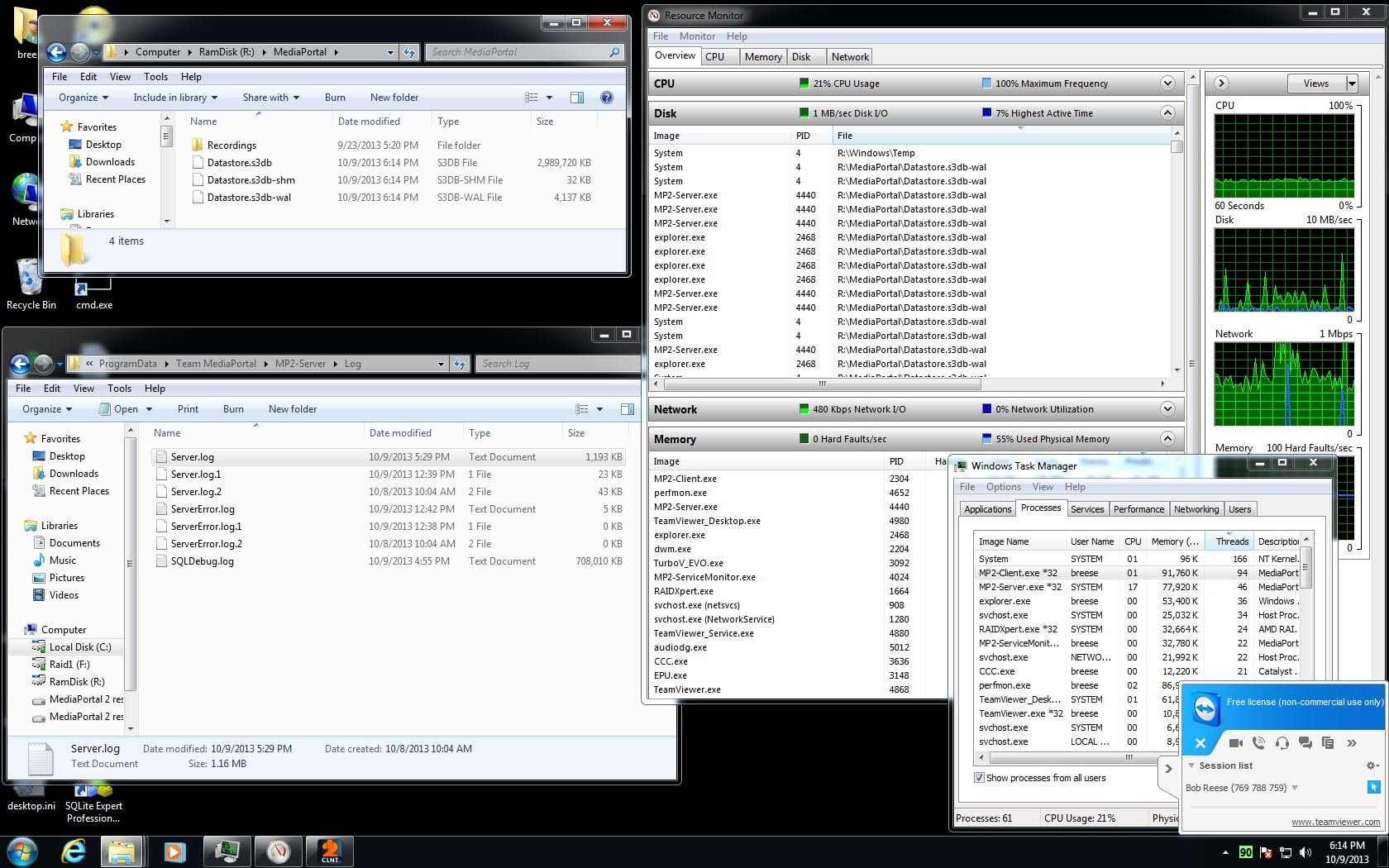
So I was looking at a few things and managed find
1st scan while installed on C: DB file 3,536,668
2nd scan while installed on F: DB file 3,221,188
So I exported the info for every song in each album and place the info into folders with Artits names.
I also looked up a very large album I have call 500 Classic Rock Songs (yep, all in 1 folder)
I included the export of that album and looking thur the logs found it took 1hr 38 minutes to scan
Every album in my collection was scanned with Tag&Rename and has a cover jpg named folder.jpg
If there is anything else you want, please let me know...
So I was looking at a few things and managed find
1st scan while installed on C: DB file 3,536,668
2nd scan while installed on F: DB file 3,221,188
So I exported the info for every song in each album and place the info into folders with Artits names.
I also looked up a very large album I have call 500 Classic Rock Songs (yep, all in 1 folder)
I included the export of that album and looking thur the logs found it took 1hr 38 minutes to scan
Every album in my collection was scanned with Tag&Rename and has a cover jpg named folder.jpg
If there is anything else you want, please let me know...
 ) try again with that one. Should be much faster...
) try again with that one. Should be much faster...