
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
DVB-S EPG wrong character encoding for Hungarian language (3 Viewers)
- Thread starter gurabli
- Start date
- Thread starter
- #72
@gurabli
i don't want to annoy you, but i'd like to clear the situation with encodings, and i need your test results")
I'm very sorry for the delay, I really try to answer asap and do things promptly. I was extremely busy in last few weeks at work, and I had to do all the necessary preparations that a soon-to-be-father needs to do at home as I'm gonna become a dad probably within a week, but it is just mater of days now
Anyway, if we do not need to go to a hospital this evening , I'm gonna do the tests and upload them today, as I would also like to have this sorted out. At lest a reason to tun on my HTPC at least- Thread starter
- #73
Here I am with the logs. For some reason, the TSWriter_EPG.log file is empty, I do not know why? Maybe because the provided tvlibrary_v0 files?
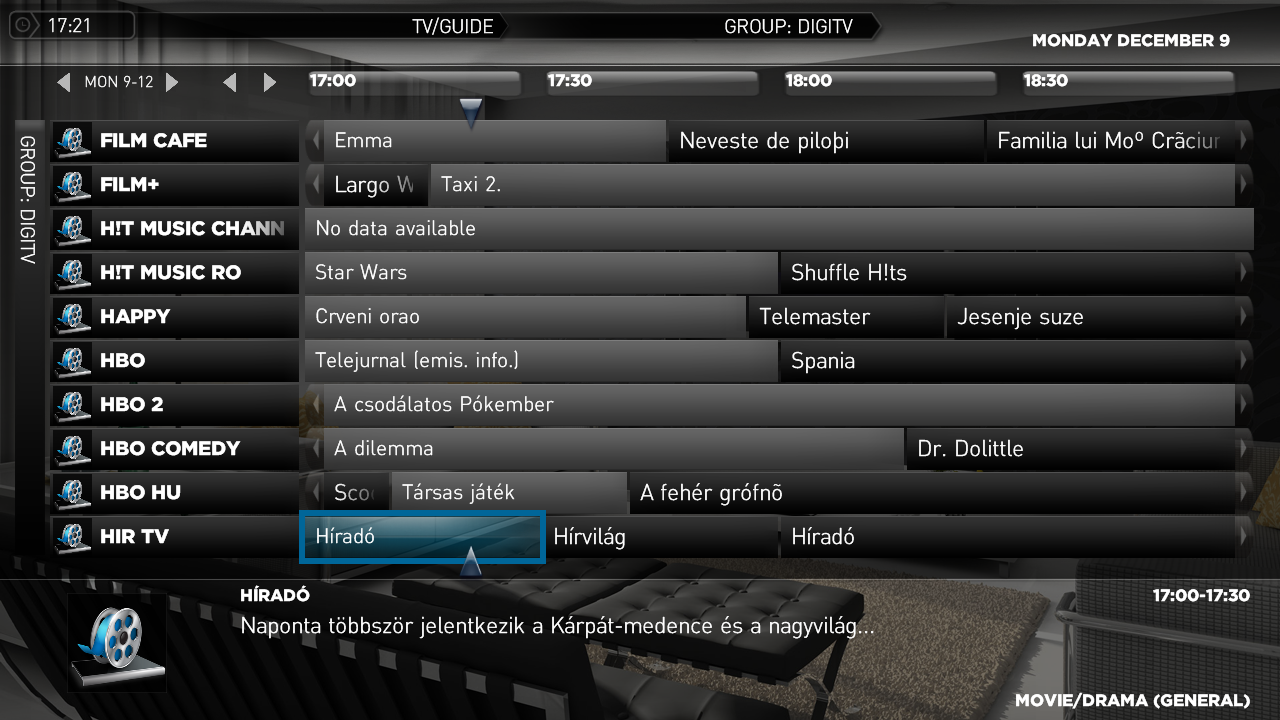
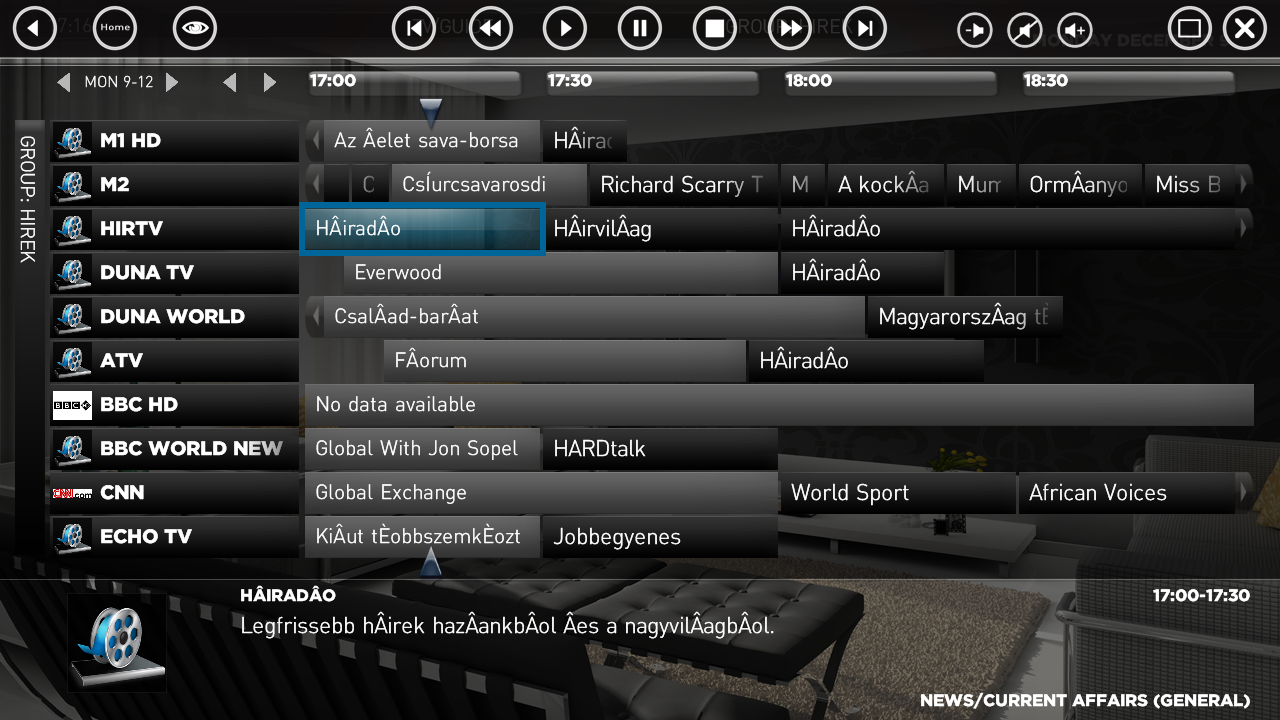
I do have the TVService logs, and the two screenshots. HírTV channel is used for both UPC and DigiTV, you can see the difference. DigiTV EPG encoding is fine, while UPC is completely wrong.
Do let me know if you requre TSWriter_EPG.log file too, perhaps with a new set of tvlibrary files.
I hope these helps you to fix this annoying issue.
UPC
HírTV 17:12 – 17:15
DigiTV
HírTV 17:18 – 17:21
I do have the TVService logs, and the two screenshots. HírTV channel is used for both UPC and DigiTV, you can see the difference. DigiTV EPG encoding is fine, while UPC is completely wrong.
Do let me know if you requre TSWriter_EPG.log file too, perhaps with a new set of tvlibrary files.
I hope these helps you to fix this annoying issue.
UPC
HírTV 17:12 – 17:15
DigiTV
HírTV 17:18 – 17:21
Attachments
- September 1, 2008
- 21,544
- 8,236
- Home Country
-
 New Zealand
New Zealand
*bump*
@Vasilich
Have you had a chance to investigate further? I'm interested to know what you find...
This afternoon I've been going through the DVB text conversion to tidy it up for TVE 3.5. I don't know if I'm going crazy here, but I noticed a couple of things that seem... well, not right.
The main functions/classes that matter for encoding (ignoring decompression - hufman stuff) are:
With one byte encoding (EN 300 468 annex A table A.3), if you have the incoming bytes...
[encoding byte] [content]
The way I read it, I think what you would get out is:
[encoding byte... if <= 0x05] [content - code points constrained to c <= 0x05, 0x20 <= c < 0x80, c >= 0x9f]
With three byte encoding (EN 300 468 annex A table A.4), if you have the incoming bytes:
0x10 0x00 [encoding byte] [content]
The way I read it, I think what you would get out is:
0x10 [encoding byte] [encoding byte... if <= 0x05] [content - code points constrained to c <= 0x05, 0x20 <= c < 0x80, c >= 0x9f]
What is the problem here?
For one byte encoding, the encoding byte will be thrown away unless it is <= 0x05. That means no support for anything other than ASCII and ISO/IEC 8859-5..9.
That is not the end of it. Consider what TV library does with three byte encoding:
TV library seems to have forgotten that the second encoding byte had to be removed in order to avoid premature NULL termination. In other words, TsWriter wrote 0x10 [encoding byte] but TV library is still expecting 0x10 0x00 [encoding byte]. This can only work if the encoding byte is <= 0x05. So it looks like ISO/IEC 8859-1..5 would work, but ISO/IEC 8859-6+ would not.
If I'm right, these are quite serious flaws.
Do you agree?
Continuing a bit further...
In the EPG text decoding we see this code:
The start of a hack if ever I saw one!
In Iso6937ToUnicode we have:
What is going on here?!?
It looks like somebody decided all Czech EPG should be decoded as ISO 6937, but then when proper DVB encoding is detected they fall back to ANSI. The hack is bad enough, but surely that PtrToStringAnsi() call should at least be replaced with DvbTextConverter.Convert().
Do you agree?
Finally, in DvbTextConverter:
Another hack.
Since language is always passed as "" (empty string), any person with OS lang/culture set to Ukranian, Belarussian or Russian will have ISO 8859-5 as default encoding. According to my understanding of EN 300 468, the default encoding should be in figure A.1 - ISO/IEC 6937 with a modification for code point 0xa4 (Euro symbol). So Czech may be the only culture that gets the proper default encoding.
In summary there seem to be some really nasty bugs and hacks in here. I don't know if any of these directly affect gurabli. Maybe you could confirm?
mm
@Vasilich
Have you had a chance to investigate further? I'm interested to know what you find...
This afternoon I've been going through the DVB text conversion to tidy it up for TVE 3.5. I don't know if I'm going crazy here, but I noticed a couple of things that seem... well, not right.
The main functions/classes that matter for encoding (ignoring decompression - hufman stuff) are:
- TsWriter:
- DvbUtil.cpp - getString468A()
- TvLibrary.Interfaces:
- DvbTextConverter.cs
- TVLibrary:
- Iso6937ToUnicode.cs
- TvCardDvbBase.cs - Epg
- Iso6937ToUnicode.cs
With one byte encoding (EN 300 468 annex A table A.3), if you have the incoming bytes...
[encoding byte] [content]
The way I read it, I think what you would get out is:
[encoding byte... if <= 0x05] [content - code points constrained to c <= 0x05, 0x20 <= c < 0x80, c >= 0x9f]
With three byte encoding (EN 300 468 annex A table A.4), if you have the incoming bytes:
0x10 0x00 [encoding byte] [content]
The way I read it, I think what you would get out is:
0x10 [encoding byte] [encoding byte... if <= 0x05] [content - code points constrained to c <= 0x05, 0x20 <= c < 0x80, c >= 0x9f]
What is the problem here?
For one byte encoding, the encoding byte will be thrown away unless it is <= 0x05. That means no support for anything other than ASCII and ISO/IEC 8859-5..9.
That is not the end of it. Consider what TV library does with three byte encoding:
Code:
byte c = Marshal.ReadByte(ptr, 0);
if (c < 0x20)
...
case 0x10:
{
pos = 3;
c = Marshal.ReadByte(ptr, 2);TV library seems to have forgotten that the second encoding byte had to be removed in order to avoid premature NULL termination. In other words, TsWriter wrote 0x10 [encoding byte] but TV library is still expecting 0x10 0x00 [encoding byte]. This can only work if the encoding byte is <= 0x05. So it looks like ISO/IEC 8859-1..5 would work, but ISO/IEC 8859-6+ would not.
If I'm right, these are quite serious flaws.
Do you agree?
Continuing a bit further...
In the EPG text decoding we see this code:
Code:
if (language.ToUpperInvariant() == "CZE" || language.ToUpperInvariant() == "CES")
{
title = Iso6937ToUnicode.Convert(ptrTitle);
description = Iso6937ToUnicode.Convert(ptrDesc);
}
else
{
title = DvbTextConverter.Convert(ptrTitle);
description = DvbTextConverter.Convert(ptrDesc);
}The start of a hack if ever I saw one!
In Iso6937ToUnicode we have:
Code:
if (b < 0x20)
{
// ISO 6937 encoding must start with character between 0x20 and 0xFF
// otherwise it is dfferent encoding table
// for example 0x05 means encoding table 8859-9
// here is just fallback to system ANSI
return Marshal.PtrToStringAnsi(ptr);
}What is going on here?!?
It looks like somebody decided all Czech EPG should be decoded as ISO 6937, but then when proper DVB encoding is detected they fall back to ANSI. The hack is bad enough, but surely that PtrToStringAnsi() call should at least be replaced with DvbTextConverter.Convert().
Do you agree?
Finally, in DvbTextConverter:
Code:
int encoding = CultureInfo.CurrentCulture.TextInfo.ANSICodePage;
try
{
if (string.IsNullOrEmpty(lang))
{
lang = CultureInfo.CurrentCulture.ThreeLetterISOLanguageName;
}
if (lang.Equals("cze") || lang.Equals("ces"))
{
encoding = 20269; //ISO-6937
}
else if (lang.Equals("ukr") || lang.Equals("bel") || lang.Equals("rus"))
{
encoding = 28595; //ISO-8859-5
}Another hack.
Since language is always passed as "" (empty string), any person with OS lang/culture set to Ukranian, Belarussian or Russian will have ISO 8859-5 as default encoding. According to my understanding of EN 300 468, the default encoding should be in figure A.1 - ISO/IEC 6937 with a modification for code point 0xa4 (Euro symbol). So Czech may be the only culture that gets the proper default encoding.
In summary there seem to be some really nasty bugs and hacks in here. I don't know if any of these directly affect gurabli. Maybe you could confirm?
mm
Nice to see that you guys are working on this... I have the same problem here with hungarian channels (upc direct). If I can help something...
completely forgotten about that one, sorry. I am short in time currently, so i will try to answer all your questions/comments, but shortly.
you've put it mildlyThis afternoon I've been going through the DVB text conversion to tidy it up for TVE 3.5. I don't know if I'm going crazy here, but I noticed a couple of things that seem... well, not right.
exactly.With one byte encoding (EN 300 468 annex A table A.3), if you have the incoming bytes...
[encoding byte] [content]
The way I read it, I think what you would get out is:
[encoding byte... if <= 0x05] [content - code points constrained to c <= 0x05, 0x20 <= c < 0x80, c >= 0x9f]
With three byte encoding (EN 300 468 annex A table A.4), if you have the incoming bytes:
0x10 0x00 [encoding byte] [content]
The way I read it, I think what you would get out is:
0x10 0x07 [encoding byte... if <= 0x05] [content - code points constrained to c <= 0x05, 0x20 <= c < 0x80, c >= 0x9f]
What is the problem here?
For one byte encoding, the encoding byte will be thrown away unless it is <= 0x05. That means no support for anything other than ASCII and ISO/IEC 8859-5..9.
not completely - in getString468A we have on lines 120-121 of trunkThat is not the end of it. Consider what TV library does with three byte encoding:
Code:byte c = Marshal.ReadByte(ptr, 0); if (c < 0x20) ... case 0x10: { pos = 3; c = Marshal.ReadByte(ptr, 2);
TV library seems to have forgotten that the second encoding byte had to be removed in order to avoid premature NULL termination. In other words, TsWriter wrote 0x10 [encoding byte] but TV library is still expecting 0x10 0x00 [encoding byte]. This can only work if the encoding byte is <= 0x05. So it looks like ISO/IEC 8859-1..5 would work, but ISO/IEC 8859-6+ would not.
If I'm right, these are quite serious flaws.
Do you agree?
Code:
text[textIndex] = 0;
bufIndex += 2;yes, there are 2 serious flaws in this code:Continuing a bit further...
In the EPG text decoding we see this code:
Code:if (language.ToUpperInvariant() == "CZE" || language.ToUpperInvariant() == "CES") { title = Iso6937ToUnicode.Convert(ptrTitle); description = Iso6937ToUnicode.Convert(ptrDesc); } else { title = DvbTextConverter.Convert(ptrTitle); description = DvbTextConverter.Convert(ptrDesc); }
The start of a hack if ever I saw one!
In Iso6937ToUnicode we have:
Code:if (b < 0x20) { // ISO 6937 encoding must start with character between 0x20 and 0xFF // otherwise it is dfferent encoding table // for example 0x05 means encoding table 8859-9 // here is just fallback to system ANSI return Marshal.PtrToStringAnsi(ptr); }
What is going on here?!?
It looks like somebody decided all Czech EPG should be decoded as ISO 6937, but then when proper DVB encoding is detected they fall back to ANSI. The hack is bad enough, but surely that PtrToStringAnsi() call should at least be replaced with DvbTextConverter.Convert().
Do you agree?
1. wrong place to do the decoding (we have dedicated function to decode this)
2. all czech EPG will be decoded using this ISO6937, independently of encoding sent by provider.
while i can understand that it can fix the encoding for some szech providers sending wrong encoding, it is still a hack.
Moreover, EN468 says that code table 00 isn't exactly ISO6937 - Euro sign is added (i fixed this locally - let me know if you are interested)
yes, another hack.Finally, in DvbTextConverter:
Code:int encoding = CultureInfo.CurrentCulture.TextInfo.ANSICodePage; try { if (string.IsNullOrEmpty(lang)) { lang = CultureInfo.CurrentCulture.ThreeLetterISOLanguageName; } if (lang.Equals("cze") || lang.Equals("ces")) { encoding = 20269; //ISO-6937 } else if (lang.Equals("ukr") || lang.Equals("bel") || lang.Equals("rus")) { encoding = 28595; //ISO-8859-5 }
Another hack.
Since language is always passed as "" (empty string), any person with OS lang/culture set to Ukranian, Belarussian or Russian will have ISO 8859-5 as default encoding. According to my understanding of EN 300 468, the default encoding should be in figure A.1 - ISO/IEC 6937 with a modification for code point 0xa4 (Euro symbol). So Czech may be the only culture that gets the proper default encoding.
In summary there seem to be some really nasty bugs and hacks in here. I don't know if any of these directly affect gurabli. Maybe you could confirm?
mm
As I see it:
we should first fix TsWriter code to pass proper encoding bytes to TVLib,
then remove hacks with czech and rus/ukr/bel owerwriting,
and pass received language code to Convert() function.
then implement all possible encodings in this function.
Only then we can think about bad providers - my idea was to read combination of NID/TSID/SID from XML file, and this XML file should be filled only by experienced users, as the problem is that these bad providers often use NID that is not intended to use by them (i have often seen NID=0x01 for those providers gurabli uses) and on different sattellites we can have same NID for different providers. Yes, i hate things that do not conform standards, but we have to live with them and try to workaround *some* of inconsistences (surely developers of software for STBs also have to deal with those, and i am almost sure they also have kinda exclusion/override tables for some providers).
The problem for gurabli is that he receives several providers, and while some are conform to DVB standards (UPC Direct), others are not. Sadly our code handles DVB-conform encoding wrong, but overrides wrong encoding - the last part i am still not understand completely how it comes that ISO8859-2 decodes properly as ANSI for hungarian (CP1252) - these tables are different. Hopefully i will get some time in next 2 weeks to understand how it can be.
- September 1, 2008
- 21,544
- 8,236
- Home Country
-
New Zealand
No problem. It is holiday time so I wasn't expecting an answer in a hurry.I am short in time currently, so i will try to answer on all your comments, but shortly.
Heh, I'm glad I'm not going crazy.you've put it mildly
To be clear, what I was thinking is that handling for three byte encoding is sometimes okay and sometimes not. It completely depends on the value of the encoding byte.not completely - in getString468A we have on lines 120-121 of trunk
so on this part textIndex wasn't changed and is =2, and bufIndex was increased from 0 to 2. This means that next char is the last, third byte of our 3-byte encoding, and just 2nd byte (=0) was replaced with 3rd one, so 0x10 0x00 0x02 [text] will be saved as 0x10 0x02 0x02 [text]. I can confirm this behavior as this is what i have seen while debugging - many polish channels (that i am able to receive) use exactly this encoding.Code:text[textIndex] = 0; bufIndex += 2;
If the input is:
0x10 0x00 [encoding byte <= 0x05] [content]
...output will be:
0x10 [encoding byte <= 0x05] [encoding byte <= 0x05] [content]
This situation is okay for TV library. It sees the encoding byte in the correct position. No problem.
However, if the input is:
0x10 0x00 [encoding byte > 0x05] [content]
...output will be:
0x10 [encoding byte > 0x05] [content]
The encoding byte is not repeated due to this condition:
Code:
else if (((c > 0x05) && (c <= 0x1F)) || ((c >= 0x80) && (c < 0x9F))) //0x1-0x5 = choose character set, must keep this byte!In this case TV library will handle the content using the default encoding, which could be wrong.
Yep, completely agree.yes, there are 2 serious flaws in this code:
1. wrong place to do the decoding (we have dedicated function to decode this)
2. all czech EPG will be decoded using this ISO6937, independently of encoding sent by provider.
while i can understand that it can fix the encoding for some szech providers sending wrong encoding, it is still a hack.
Yes, I'd definitely be interested.Moreover, EN468 says that code table 00 isn't exactly ISO6937 - Euro sign is added (i fixed this locally - let me know if you are interested)
I also have some questions already. Mainly I'm trying to understand if there is any reason to keep the Iso6937ToUnicode class.
If we want to conform with EN 300 468, is it technically correct to replace this code in TvCardDvbBase.cs:
https://github.com/MediaPortal/Medi...ementations/DVB/Graphs/TvCardDvbBase.cs#L2638
Code:
if (language.ToUpperInvariant() == "CZE" || language.ToUpperInvariant() == "CES")
{
title = Iso6937ToUnicode.Convert(ptrTitle);
description = Iso6937ToUnicode.Convert(ptrDesc);
}
else
{
title = DvbTextConverter.Convert(ptrTitle, "");
description = DvbTextConverter.Convert(ptrDesc, "");
}...simply with:
Code:
title = DvbTextConverter.Convert(ptrTitle);
description = DvbTextConverter.Convert(ptrDesc);...and, replace this code in DvbTextConverter.cs:
https://github.com/MediaPortal/Medi....Interfaces/DvbTextConverter.cs?source=cc#L40
Code:
int encoding = CultureInfo.CurrentCulture.TextInfo.ANSICodePage;
try
{
if (string.IsNullOrEmpty(lang))
{
lang = CultureInfo.CurrentCulture.ThreeLetterISOLanguageName;
}
lang = lang.ToLowerInvariant();
if (lang == "cze" || lang == "ces")
{
encoding = 20269; //ISO-6937
}
else if (lang == "ukr" || lang == "bel" || lang == "rus")
{
encoding = 28595; //ISO-8859-5
}...with:
Code:
encoding = 20269; // default/base: ISO-6937This doesn't fix:
- the bugs in TsWriter
- the Marshal.ReadByte(ptr, 2) bug in DvbTextConverter
- the Euro sign exception
Do you agree?
Completely agree.we should first fix TsWriter code to pass proper encoding bytes to TVLib,
then remove hacks with czech and rus/ukr/bel owerwriting,
Is this necessary, or just maybe useful for dealing with bad providers? From what I can see in EN 300 468, there is no need for an ISO 639 code to tell us how to decode.and pass received language code to Convert() function.
I agree. I think we can consider such a solution, but it depends how bad the problem is. If we only have a few reports of problems after fixing the code then maybe we can just ask those people to use some other EPG source. I prefer that over adding configuration because so many people say that TV Server configuration is complicated enough already...Only then we can think about bad providers...
mm
well, yes and no. The problem with 20269 is that it is just wrongly implemented in .NET - i first have read it somewhere, and then tested - 20269 uses wrong byte order when decoding, so we need our own class to decode it properly. I'll post that code i used for decoding - it implements proper decoding for ISO 6937 (based on Iso6937ToUnicode), 8859-10 and 8859-14 (that are missing in .NET) tonight.I'm simply trying to understand whether it is safe/okay to remove Iso6937ToUnicode.cs. To me it looks like it should be okay, and we can just fix the Euro sign encoding manually.
Do you agree?
just for dealing with bad providers, as the language code itself doesn't contain info about encoding.Is this necessary, or just maybe useful for dealing with bad providers? From what I can see in EN 300 468, there is no need for an ISO 639 code to tell us how to decode.and pass received language code to Convert() function.
we need to get statistic after fixing that, and then we can decide whether to implement some workarounds, agree.If we only have a few reports of problems after fixing the code then maybe we can just ask those people to use some other EPG source
Last edited:
- September 1, 2008
- 21,544
- 8,236
- Home Country
-
New Zealand
Wow, okay. Interesting!well, yes. The problem with 20269 is that it is just wrongly implemented in .NET - i first have read it somewhere, and then tested - 20269 uses wrong byte order when decoding, so we need our own class to decode it properly. I'll post that code i used for decoding - it implements proper decoding for ISO 6937 (based on Iso6937ToUnicode), 8859-10 and 8859-14 (that are missing in .NET) tonight.I'm simply trying to understand whether it is safe/okay to remove Iso6937ToUnicode.cs. To me it looks like it should be okay, and we can just fix the Euro sign encoding manually.
Do you agree?
These sorts of things should be added as comments in the code. I'd be interested to read the link/blog/whatever if you can remember where you read it.
Looking forward to reading your code.
i grab it from browser historyI'd be interested to read the link/blog/whatever if you can remember where you read it.
Not all code pages work right - Sorting it all Out - Site Home - MSDN Blogs
http://blogs.msdn.com/b/michkap/archive/2005/01/22/358675.aspx
unfortunately, this blog is not there anymore
i will try to find the code i used for testing 20269, so you also can see the problem.
Users who are viewing this thread
Online now: 2 (members: 0, guests: 2)